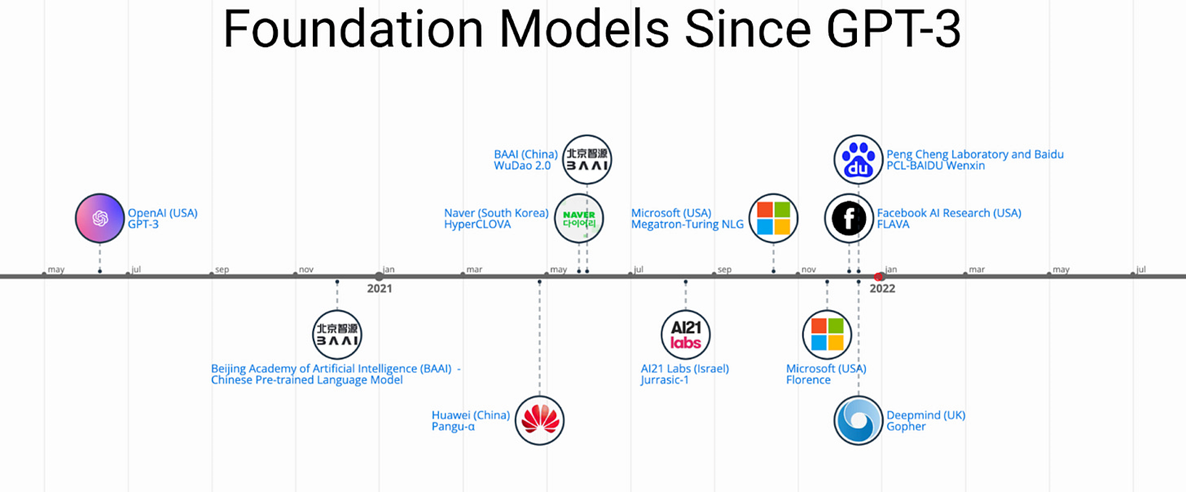
Intro 요즘 사회적으로 가장 핫한 주제가 ChatGPT와 같은 Foundation Model이다. 불과 몇 년 전만 해도 AI를 사용해서 실질적인 이익을 얻는 것은 아직 시간이 걸릴 것이라는 의견이 많았는데 OpenAI의 ChatGPT 열풍으로 변곡점을 맞이한 듯하다. 뿐만 아니라 최근 나오는 이미지 생성 모델들 또한 엄청난 성능을 보이며 많은 이들이 사용하고 있다. 덕분에 많은 기업들이 빅 모델(big model)을 만드는 것에 뛰어들고 있다(Fig 1). 이번 글에서는 자연어 생성 모델은 생략하고 이미지 생성(stable diffusion)과 이미지 분류(CLIP)에 관한 모델과 big 모델을 튜닝하기 위한 몇 가지 알고리즘을 소개한다. Zero-shot Image Classification GP..