Intro
Pruning은 neural network를 경량화하고자 할 때 사용하는 방법입니다. Figure 1은 pruning을 잘 보여주는 그림입니다. 모든 node가 연결이 되어있던 왼쪽 그림으로 오른쪽과 같이 synapse(혹은 edge)와 neuron(혹은 node)를 없애는 것입니다. 당연히 무작정 없애면 안 되고 보통은 parameter가 0에 가깝다거나 훈련을 거의 안 했다거나 하는 지표를 가지고 판단하여 pruning 하게 됩니다. 실제로는 그림처럼 아예 없앤다고 이해하기보다 0으로 만들었다고 생각하면 됩니다. (이는 pruning 방법에 따라 아예 없앨 수도 있긴 합니다.)

Method
Structured vs Unstructured
Pruning은 경량화를 위한 필수 방법인만큼 여러 방법들이 연구되어 오고 있습니다. 대표적으로 unstructured pruning과 structured pruning입니다. figure 2를 보면 두 알고리즘의 차이가 보입니다.
왼쪽의 structured 방법은 대표적으로 channel pruning([1])이 있는데 convolution network에서 상대적으로 필요 없는 channel을 뽑아서 없애는 방법입니다. 이런 식으로 structured pruning은 어떤 구조를 통째로 날려버리는 방법입니다. 이 방법의 장점은 구조를 날리는 것이니 matrix 연산을 안 해도 되므로 pytorch, tensorflow 같은 프레임워크와 잘 호환되어 inference 속도를 개선할 수 있다는 것입니다. 하지만 단점으로는 구조를 통째로 날리는 것이다 보니 pruning 하는 비율을 높게 하기는 어렵다는 것입니다.
오른쪽 그림의 unstructured 방법은 figure 1에서 보았던 그림과 같이 구조와 상관없이 그냥 특정 기준을 세워서 (보통 0 근처의 weight) 가지치기하듯 weight를 0으로 만들어버리는 것입니다. 이 방법의 장점은 필요 없다고 판단되는 weight를 0으로 만드는 것이라 높은 비율로 pruning 할 수 있다는 것입니다. 뒤에서 보겠지만 95%까지 pruning 하더라도 좋은 성능을 내곤 합니다. 하지만 단점으로는 pruning을 했으나 실제로는 0의 값을 가지므로 기존의 프레임워크를 사용하여 matrix 연산을 할 때 계산을 하긴 해야 하므로 실질적인 inference 속도를 개선하지는 못합니다.

RETHINKING THE VALUE OF NETWORK PRUNING
Unstructured pruning 방법과 Structured pruning 방법은 장, 단점이 반대이기도 하며 해석하는 시각도 조금 다릅니다. 보통 pruning은 훈련을 Initialize -> Train -> Pruning -> Finetuning의 방식으로 진행하곤 합니다. 이는 여러 논문에서 나온 실험 결과를 보면 알 수 있습니다. 하지만 이는 Unstructured pruning 방법에 해당하며 Structured pruning은 Initialize -> Train -> Pruning -> Initialize -> Train의 방식이 더 좋다고 [2] 논문에서는 주장합니다. [2] 논문에서는 이를 통해 Structured pruning 방법으로 찾은 weights 보다는 남아있는 구조가 중요하며 이는 Neural Architecture Search로도 활용할 수 있음을 보여주었습니다. Pruning으로 얻은 구조는 실제로 좋은 성능을 보여주었고 이는 신선하고 좋은 아이디어인 것 같습니다.
Lottery ticket hypothesis
한편, Unstructured pruning 방법임에도 Finetuning을 하지 않고 다시 initialize를 통해 훈련을 한 모델이 오히려 더 좋은 성능을 낸다는 연구도 있습니다([3]). 다만, 이 논문은 기존과는 조금 다르게 initialize를 처음 train 하기 전 parameter로 다시 돌려보내어 훈련하는 것을 가정합니다. Figure 3을 보면 이에 대한 알고리즘이 잘 나와 있습니다. 이 논문에서는 커다란 neural network 안에는 여러 개의 sub network가 있으며 그 안에는 성능이 원래의 모델과 비슷하거나 더 좋은 모델이 있다고 가정합니다. 그리고 그런 sub network를 winning ticket이라고 칭합니다. 이런 winning ticket은 훈련 후 pruning 하여 구할 수 있고 처음 initialize로 돌려보내어 학습하면 상당히 좋은 성능을 얻을 수 있다고 보여줍니다.

Gradient Flow in sparse neural networks
그렇다면 pruning 후 random initialize 하여 훈련하는 것과 이렇게 다시 처음의 initialize로 돌려서 훈련하는 것, structured pruning 방법은 무엇이 다르기에 이렇게 다른 성능을 보여주는 것일까요? 이는 ([4]) 논문에서 잘 보여줍니다.
Unstructured pruning 후 fintuning이 아닌 random initialize를 했을 때 성능이 좋지 않았던 이유는 initialize를 제대로 해주지 않았기 때문입니다. Neural network의 initialize는 훈련 시 굉장히 중요하여 연구도 많이 이루어지고 있습니다. 현재는 Xavier 혹은 He initialize를 쓰고 있습니다. 그런데 이는 모든 node가 잘 연결되어 있을 때 사용하는 방법입니다. figure 4를 보면 왼쪽과 같은 dense layer는 기존의 initialize가 잘 통하지만 오른쪽과 같이 pruning을 했을 경우는 다르게 initialize 해야 한다는 얘기입니다. 그래서 논문에서는 각 output node 별로 연결된 노드를 따로 계산하여 initialize 하는 방식을 제안하고 실제로 성능을 개선시키는 데 성공합니다.
Figure 5에는 spare layer에서 기존과 같이 initialize를 하면 훈련 시작 시 gradient norm이 굉장히 작아 학습이 어렵다는 사실을 보여줍니다. Scratch가 기존의 initialize를 사용한 것이고 Scratch+가 이들이 제안한 initialize 방법으로 학습한 것입니다. 한편 Lottery 방법은 Scratch와 비슷하게 gradient norm이 작음을 알 수 있습니다. 그렇다면 Lottery는 왜 잘되는 것일까요?


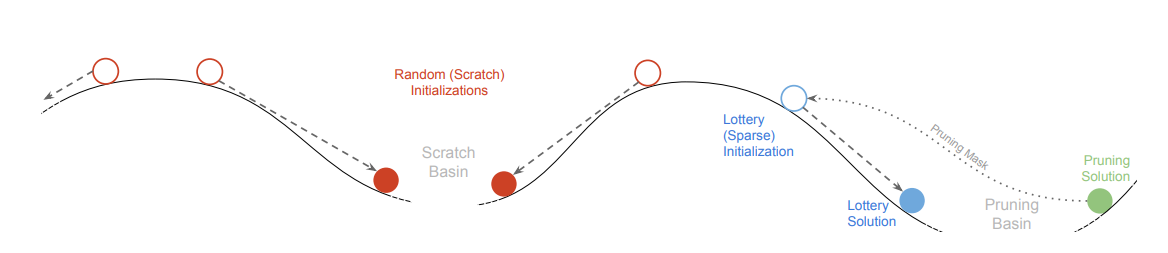
그 이유는 figure 6에 나와 있습니다. Lottery는 initialize를 했을 때 random initialize 보다 pruning solution에 가까웠고 학습한 후에는 훨씬 가까워져서 같은 basin안에 들어가게 된다는 것입니다. 여러 번 반복하여도 같은 결과를 얻는다고 합니다. 그러니 정리하면 기존의 unstructured pruning 방법은 initialize 문제로 random initialize 후 재학습했을 때 잘 작동하지 않았으며, Lottery ticket 방법은 애초에 잘 배웠던 대로 재학습을 했기 때문에 좋은 성능을 보였던 것입니다. 이는 lottery ticket 논문이나 rethinking the value of network pruning 논문에서 learning rate를 작게 했을 때 winning ticket의 성능이 좋았다는 결과와 통합니다. Initialize point에서 멀리 갈수록 다시 re-learning 하기 어려울 것이므로 winning ticket이 잘 작동하지 않는 것입니다.
각 Pruning 방법들은 장, 단점이 존재하여 잘 알아두면 좋은 것 같고 neural network를 이해하는 데 도움이 많이 됩니다. 앞으로도 좋은 논문이 나오면 많이 리뷰를 해보겠습니다.
Reference
[1] https://arxiv.org/abs/1707.06168
Channel Pruning for Accelerating Very Deep Neural Networks
In this paper, we introduce a new channel pruning method to accelerate very deep convolutional neural networks.Given a trained CNN model, we propose an iterative two-step algorithm to effectively prune each layer, by a LASSO regression based channel select
arxiv.org
[2] https://arxiv.org/abs/1810.05270
Rethinking the Value of Network Pruning
Network pruning is widely used for reducing the heavy inference cost of deep models in low-resource settings. A typical pruning algorithm is a three-stage pipeline, i.e., training (a large model), pruning and fine-tuning. During pruning, according to a cer
arxiv.org
[3] https://arxiv.org/abs/1803.03635
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Neural network pruning techniques can reduce the parameter counts of trained networks by over 90%, decreasing storage requirements and improving computational performance of inference without compromising accuracy. However, contemporary experience is that
arxiv.org
[4] https://arxiv.org/abs/2010.03533
Gradient Flow in Sparse Neural Networks and How Lottery Tickets Win
Sparse Neural Networks (NNs) can match the generalization of dense NNs using a fraction of the compute/storage for inference, and also have the potential to enable efficient training. However, naively training unstructured sparse NNs from random initializa
arxiv.org
'머신러닝&딥러닝 > 기초정리' 카테고리의 다른 글
| 다양한 Hyperparameter Optimization 방법 리뷰 (1) | 2022.03.12 |
|---|---|
| Graph Neural Network 설명 - Introduction to GNN (0) | 2022.02.25 |
| Multi-task learning & Meta-learning (0) | 2021.09.23 |
| Likelihood, Maximum likelihood estimation 이란? (0) | 2021.08.29 |
| Variational AutoEncoder란? (0) | 2020.11.29 |