오토인코더의 모든 것(youtube) - 이활석
Variational AutoEncoder와 ELBO(blog) - Seon Guk
"Auto-Encoding Variational Bayes"(2014) - Kingma et al.
"An Introduction to Variational AutoEncoders(2019)" - Kingma et al.
이활석님의 명강의 '오토인코더의 모든 것' , VAE와 ELBO에 대해 슬라이드로 잘 정리한 블로그, Variational AutoEncoder(VAE)에 대한 논문을 참조하였다.
VAE는 Autoencoder와는 다르게 latent variable을 Gaussian 분포 같이 잘 알려진 Prior 분포를 설정하고 거기에 맞출 수 있어서 이미지 등을 만들 때 편리한 생성 모델이다. 이를 이해하기 위한 기초 개념들이 중요한 것이 많아 정리한 것을 남긴다.
VAE 구조
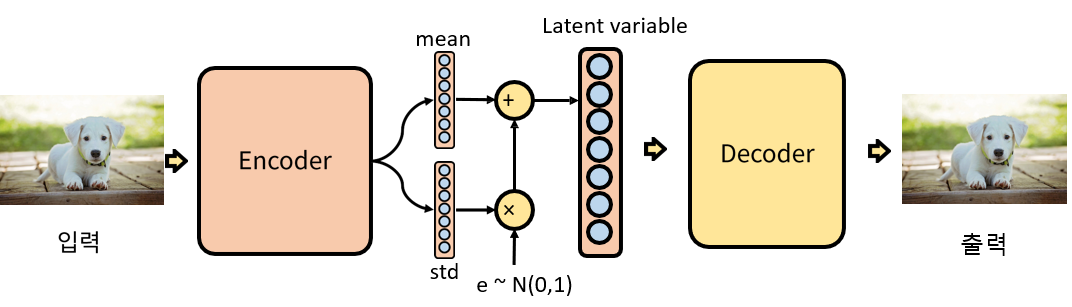
위의 그림은 VAE의 과정을 표현한 것이다. 강아지 사진이 입력으로 들어가면 Encoder에서 데이터에 대한 분포를 나타내는데, 가우시안 분포를 가정하여 mean과 std로 출력한다. 이 분포에 대한 데이터를 전부 사용할 수 없으니 샘플링을 하게 되고 이때 Reparameterization trick을 사용한다. Reparameterization trick은 $\epsilon$을 N(0,1)에서 샘플링해서 std에 곱해주고 mean과 더해주는 방법으로 샘플링을 직접 하는 것을 막는 방법이다. 이것을 사용하지 않으면 출력된 mean과 std에 대한 가우시안 분포에서 직접 샘플링을 해야 하는데 그렇게 되면 deterministic하지 않기 때문에 역전파가 불가하다. 이에 대한 그림은 아래와 같다.

샘플링한 Latent variable은 z라고 부르고 이것을 사용해 Decoder를 통과시켜 원래 데이터를 생성시키게 된다. AutoEncoder는 Manifold로 차원 축소를 잘 해내는 것이 목적이지만 Variational AutoEncoder는 latent variable z가 Gaussian distribution을 따른다고 가정하여 생성에 쓰고자 하는 것이 목적이다. z는 gaussian 분포이므로 나중에 굳이 Encoder를 사용하지 않고 뽑고 싶은 데이터에 대해 gaussian 샘플링을 해주면 되므로 생성 모델에 적합하다.
Encoder - x를 잘 나타내는 z를 생성하는 sampling 함수 $q_{\phi}$
VAE는 데이터 셋에 있는 데이터들과 유사한 분포를 가지는 데이터를 생성하는 것이 목적이다. 그런데 데이터 x를 잘 나타내는 함수가 필요하다. 이런 함수를 직접 구하진 못하므로 잘 알고있는 함수(ex. gaussian) $q_{\phi}$를 근사시키는 Variational Inference 방법을 적용한다.
모든 x에 대해 z가 생성될 확률은 1이므로 $ \int q(z|x) dz = 1 $로 표현 가능하다. 그러므로 P(x)에 log를 취해서 식을 전개해보면 다음과 같이 표현된다.
$$ log P(x) = log P(x) \int q(z|x) dz $$
$$ = \int q(z|x) log P(x) dz $$
베이즈 룰에 의해 $ log P(x) = log \frac {P(x|z) P(z)} {P(z|x)} = log P(x|z) + log P(z) - log P(z|x) $ 이므로 위의 식을 다음과 같이 전개한다.
$$ = \int q(z|x) [log P(x|z) + log P(z) - log P(z|x)] dz $$
$$ = \int q(z|x) log P(x|z) dz + \int q(z|x) (log P(z) - log P(z|x)) dz \pm \int q(z|x) log q(z|x) dz $$
확률 밀도 함수 $ q(z|x) $ 를 따르는 x에 대한 P(x|z)의 기댓값은 q(z|x)를 따르는 샘플들로 근사할 수 있다. 이를 Monte Carlo Approximation이라고 하며 다음과 같이 나타낼 수 있다. $ \int q(z|x) log P(x|z) dz = E_{q(z|x)} [log P(x|z)] $ 이를 위의 식에 반영하면 다음과 같다.
$$ = E_{q(z|x)}[log P(x|z)] - \int q(z|x) logq(z|x) dz + \int q(z|x) log q(z|x) dz + \int q(z|x) log P(z) dz $$
$$ + \int q(z|x) log q(z|x) dz - \int q(z|x) log P(z|x) dz $$
이제 $ KL(p, q) = \int p(x) log p(x) dx - \int p(x) log q(x) dx $식을 이용하여 식을 바꿔주면 다음과 같다.
$$ = E_{q(z|x)} [log P(x|z)] - KL(q(z|x), P(z)) + KL(q(z|x),P(z|x)) \cdots (1)$$
마지막 항의 P(z|x)는 x의 분포가 매우 복잡하여 나타내지 못하므로 구하지 못한다. 따라서 생략하여 표현하고 KL-divergence는 항상 0보다 큰 값을 가지므로 최종적으로 다음과 같이 표현할 수 있다.
$$ log P(x) \ge E_{q(z|x)} [log P(x|z)] - KL(q(z|x),P(z)) $$
데이터 x가 나올 확률 P(x)를 최대화하면 Network를 잘 학습시킨다고 할 수 있다. 위의 식을 앞으로 Evidence Lower Bound(ELBO)라고 부른다.
다른 해석도 가능하다.

(1)식에서 마지막 항 $ KL(q_{\phi}(z|x), P(z|x)) $는 z가 x를 잘 표현하는 이상적인 sampling 함수 P와 $q_{\phi}$ 함수의 거리를 나타낸다. 이 두 함수의 차이를 줄이면(KL을 minimize 하면) 이상적 sampling 함수에 가까워지는 $q_{\phi}$를 얻게 되는데 P(z|x)는 x의 분포가 매우 복잡하여 구하지 못한다. 대신 위의 그림처럼 ELBO를 Maximize 하여 간접적으로 $KL(q(z|x), P(z|x))$를 minmize 하는 방법을 사용한다. 이를 Variational Inference라고 한다.
Decoder - z로부터 x를 잘 생성하는 함수 $g_{\theta}$
Decoder에 z를 줬을 때 x가 나오게 나올 확률을 maximize 하게 해야 한다. 식으로는 $ E_{q_{\phi}(z|x)}[log (P(x|g_{\theta}(z))]$가 된다. 이는 Likelihood를 Maximize 하는 문제가 되어 풀 수 있다. ($q_{\theta}$를 통과한 값이 어떤 분포를 가정하냐에 따라 다른 loss function을 사용한다. gaussian(sigma=1인)이라면 mse, bernoulli 라면 cee를 사용한다(자세한 내용은 여기를 참조))
그런데 수식으로 보면 이미 ELBO안에 들어가 있다. 그러므로 최종 optimization 식은 다음과 같다.
$$ argmin_{\phi, \theta} \sum_{i} -E_{q_{\phi}(z|x_{i})}[log(P(x_{i}|g_{\theta}(z)))] + KL(q_{\phi}(z|x_{i})|P(z)) $$
첫 항은 Reconstruction Error로 x로부터 z를 생성하였고 z를 decoder에 넣었을 때 데이터 x를 얼마나 잘 생성해 냈는지를 의미한다.
두 번째 항은 Regularization term으로 데이터 x가 Encoder를 통해 나온 z가 P(z)와 유사하게 분포하도록 만들어 준다. 이는 나중에 모델을 생성할 때 사용하는데 편리함을 준다. P(z)와 $q(z|x)$는 gaussian distribution을 가정하므로 KL-divergence를 쉽게 구할 수 있다(자세한 내용은 여기를 참조).
Encoder $q_{\phi}$의 출력은 gaussian, Decoder $g_{\theta}$의 출력은 beroulli를 따른다고 가정하면 각각의 Error는 다음과 같이 계산된다.
$$ Reconstruction Error : -\sum_{j=1}^{D} x_{i, j} log p_{i, j} + (1-x_{i, j}) log (p-p_{i, j}) $$
$$ Regularization term : \frac {1} {2} \sum_{j=1}^{J}(\mu_{i, j}^{2} + \sigma_{i, j}^{2} - ln(\sigma_{i, j}^{2})-1)$$
'머신러닝&딥러닝 > 기초정리' 카테고리의 다른 글
| Multi-task learning & Meta-learning (0) | 2021.09.23 |
|---|---|
| Likelihood, Maximum likelihood estimation 이란? (0) | 2021.08.29 |
| KL-divergence with Gaussian distribution 증명 (0) | 2020.11.26 |
| Auto Encoder란? - Manifold와 차원 축소 (0) | 2020.03.29 |
| Mean Squared Error VS Cross Entropy Error (3) | 2020.03.28 |