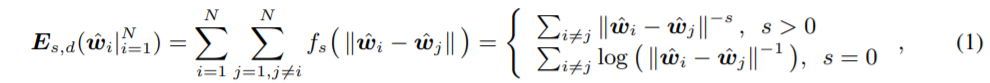"Learning towards Minimum Hyperspherical Energy" (2018, NIPS) - Liu et al. 이 논문은 효율적인 neural network 학습을 위해 서로 다른 neuron이 나타내는 feature 사이의 distance가 증가하게 하고 그로 하여금 generalization 성능을 이끌어 내려고 한다. Introduction 최근 Neural Network 관련 paper들을 보면 크면 클수록(over parameterization) 잘 된다라고 한다. 그런데 한편으로는 클수록 correlation이 높은 neurons가 많아서 redundant 하다고도 한다. 그래서 큰 모델을 학습시키고 Pruning을 시켜 compression 하는 방법이나 efficie..