"Sharpness-Aware Minimization for Efficiently Improving Generalization" (2020, google research)
Introduction
이번 논문은 flat minima를 찾아 Generalization 성능을 이끌어내는 알고리즘을 제안한 논문이다. Flat minimum의 loss는 주위 loss와 차이가 별로 나지 않을 것임을 안다. 이런 조건을 만족하도록 optimize 하는게 핵심이다.
기존부터 loss landscape은 generalization 논문에서 자주 등장한다. 보통의 경우 landscape이 flat 할수록 general 한 성능을 보이고 sharp 할수록 그렇지 않다고 주장한다 (보통의 경우라 한 이유는 그 반대의 주장을 하는 논문도 있기 때문이다). 이는 직관적으로 말이 되는데 아래 <그림 1>과 같은 경우를 생각하면 된다. Tr은 Train set에 대한 loss landscape이며 Te는 Test set에 대한 loss landscape이다. 왼쪽은 flat 한 경우이고 오른쪽은 sharp 한 경우이다. Test set과 Train set이 달라서 landscape이 살짝 shift 되었다고 가정한다. flat 한 경우 test set에 대한 loss 값은 train set의 optimal loss와 많이 차이 나지 않지만 sharp 한 경우에는 많이 차이가 나게 된다.

그러므로 보통 flat minima를 찾고 싶어 하고 이 논문에서도 그런 방법을 제시한다.
Objective Function

Theorem 1 에서 training method를 유도한다. Data의 distribution이 D이고 거기서 (i.i.d condition에서) sampling 된 training set S 가 있을 때 Loss 간의 관계를 나타낸 것이다. Generalization이 극대화되기 위해서는 Data set D에 대한 Loss (즉 $L_{D}(w)$)가 minimize 돼야 한다 (test set을 잘 맞추는 게 목적이므로 너무 당연). 그래서 오른쪽 항을 minimize 하여 $L_{D}(w)$도 함께 minimize 하려고 하는데 오른쪽 항은 사실 sharpness와 관련된 식이다 (아래 식을 보면 그렇다).

Theorem 1의 오른쪽 항을 위의 식처럼 표현 가능한데 대괄호 안의 항이 sharpness와 관련이 있게 된다. 설명하면 이렇다. ($\epsilon$은 perturbation 을 표현한다.) weight perturb (loss가 커지게 만드는)를 줬을 때의 loss와 그렇지 않았을 때의 loss 차이를 보는 것이므로 perturb에 민감하면 (loss landscape이 sharp 하면) 값이 커질 것이고 둔감하면 (loss landscape이 flat 하면) 값이 작아질 것이다. 이는 <그림 1>에서 생각해본 것과 같다.
그러므로 위의 식을 optimize 하면 결국 flat minima를 찾게 된다. 정확한 알고리즘은 밑에서 설명한다.
Algorithm
좀 더 복잡한 내용들이 논문에 있지만 생략하고 실제 알고리즘을 어떻게 쓰는지를 보겠다.

논문에 나온 알고리즘 과정은 위와 같은데 쉽게 그림을 보면서 이해해보겠다.
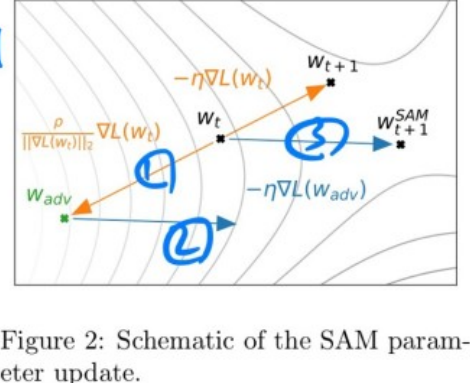
그림 위의 숫자는 알고리즘이 진행되는 순서를 나타낸다. 첫번째로 $W_{t}$에서 loss가 maximize 되도록 만드는 perturb를 구하고 $W_{adv}$로 gradient ascent 한다. 두 번째로 $W_{adv}$에서 loss가 minimize 되도록 만드는 기울기를 구한다. 마지막으로 $W_{t}$에서 두 번째에서 구한 기울기로 gradient descent를 하면 알고리즘이 끝난다. 간단하면서도 직관적인 알고리즘인데 성능도 SOTA를 이뤘다 (논문 참조). 결과에서는 모델이 얼마나 Robust 하게 만들어졌는지를 테스트해보기도 하고 $\lambda_{max}$를 구해서 flat 한 정도도 찾아보며 검증을 많이 했는데 따로 첨부하지는 않는다. Robust 한 모델을 research 중이라면 한 번쯤 볼만한 논문인 것 같다.