이번 글에서는 Auto Encoder를 공부하면서 익힌 내용들을 정리한다.
Auto Encoder는 Encoder와 Decoder의 구조로 되어있는데 PCA와 같은 차원 축소가 그 목적이었다. 그러므로 사실 핵심은 Encoder에서 Latent variable을 생성하는 것에 있다.
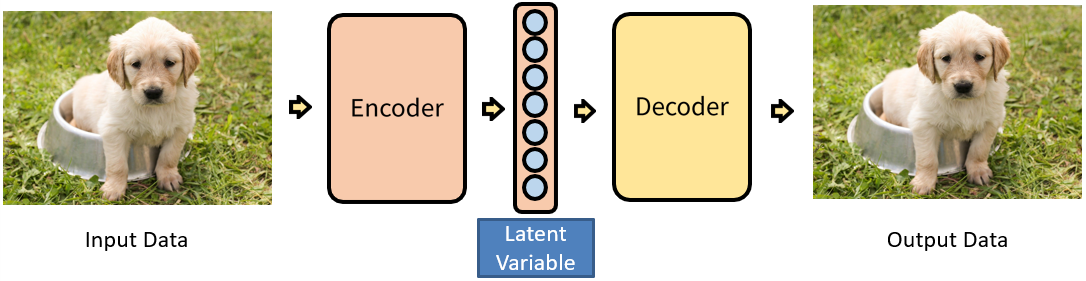
Latent Variable은 Input으로 넣은 Data의 차원을 축소시켜서 만든 벡터인데 언뜻 생각했을 때 정보가 많이 손실돼서 안 좋은 거 아닌가?라고 생각할 수 있다. 이를 이해하기 위해 차원의 저주를 먼저 알 필요가 있다.
차원의 저주는 Data의 개수는 별로 없는데 이를 설명하려고 하는 변수의 차원은 클 때 일어난다. 예를 들어 데이터가 5개밖에 없는데 이를 설명하려는 길이 10인 벡터를 갖는 Parameter 개수가 1개(1-D), 2개(2-D), 3개(3-D) 일 때, 각각 $\frac{데이터}{차원}$과 차원에 대한 데이터 밀도값을 계산해보면 $\frac{5}{10^{1}}=50$%, $\frac{5}{10^{2}}=5$%, $\frac{5}{10^{3}}=0.5$%가 된다. 즉, 차원이 늘어갈수록 사용하는 공간대비 아는 정보에 대한 밀도가 희박해진다. 따라서 차원이 증가할수록 데이터 분석에 필요한 데이터 수가 기하급수적으로 늘어나게 된다.
이제, Mnist의 숫자 이미지를 생각해 볼 때, 이미지 크기가 28*28이므로 그것을 설명하는 파라미터는 784개이다. 그렇다면 임의의 분포로 각 픽셀에 데이터를 뿌릴 때 경우의 수는 굉장히 많을 테지만 한번쯤은 Mnist 데이터와 비슷한 숫자 이미지가 나오지 않을까?라고 생각할 수 있다. 하지만 꽤 많이 실행해봐도 Noise 가득한 형체 없는 이미지만이 나올 뿐이다. 여기서 가정을 할 수 있는데, 우리가 알고 있는 깨끗한 이미지들은 Normal하게 분포하지 않고 Dense 한 어떤 특정한 지역에 분포한다는 것이다. 그렇다면 우리는 Random 하게 그런 이미지들을 찾기가 힘들 것이다.
위의 두 설명을 결합하면 Manifold 가정을 이끌어 낼 수 있다. 고차원의 데이터 밀도는 낮지만 이들의 집합을 포함하는 저차원의 SubSpace가 있다는 것이다. 그리고 이 저차원의 Manifold를 벗어나는 순간부터 급격히 밀도가 낮아져 이미지를 잘 설명하지 못하게 된다.
(참고로 Manifold는 고차원의 데이터를 저차원으로 옮길 때 데이터를 잘 설명하는 집합의 모형이다. 또한 높은 차원에서 낮은 차원으로 변환하는 것을 Embedding 이라고 하며 그것에 대한 학습 과정을 Manifold Learning이라고 한다.)
그러므로 Encoder에서는 Mainfold 가정을 통해 Input Data의 고차원 데이터는 희박한 밀도를 가지고 있으므로 저차원의 데이터로 만들어서 원래의 데이터를 잘 설명하는 Manifold를 찾는 것이 목적이다. 그렇다면 Decoder는 왜 존재하는가? 그 이유는 Decoder로 Latent Variable을 원래의 Data로 만들어 주게 되면 Label로 다시 input data를 사용할 수 있으므로 지도 학습이 가능해지기 때문이다. 지금은 Auto Encoder가 생성 모델로도 쓰이고 Denoising으로도 사용이 되는데 괜찮은 성능을 보인다.
'머신러닝&딥러닝 > 기초정리' 카테고리의 다른 글
| Variational AutoEncoder란? (0) | 2020.11.29 |
|---|---|
| KL-divergence with Gaussian distribution 증명 (0) | 2020.11.26 |
| Mean Squared Error VS Cross Entropy Error (3) | 2020.03.28 |
| 경사하강법 이해(2) - Learning Rate란? (0) | 2020.03.28 |
| Convolution Neural Network 원리와 구조 이해 (0) | 2020.01.03 |