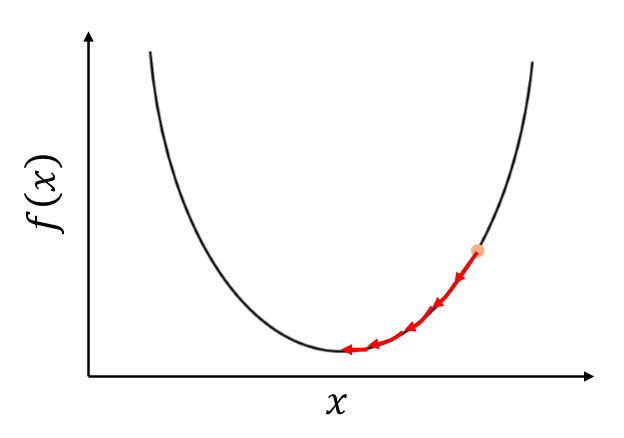
인공지능 모델의 전체적인 과정을 보면 다음과 같다. 데이터 입력 => 파라미터(weight, bias)를 통한 output 도출 => loss값 생성(label값과 prediction값의 차이 이용) => loss를 줄기 위해 기울기를 이용한 최적화(경사 하강법 적용, parameter 갱신) * loss를 구하고 경사하강법을 적용하는 것이 모델 학습의 핵심이다. 파라미터 weight과 bias를 이용하여 x를 input으로 주었을 때, H(x)=Wx+b의 output을 내게 된다. 이때 H(x) 값과 Label값을 비교하여 Loss를 생성한다. 대표적인 Loss 함수 Mean Squared Error를 이용한다고 했을 때, 식이 다음과 같다. MSE = Mean((H(x)-Label)^2)/2 = Me..