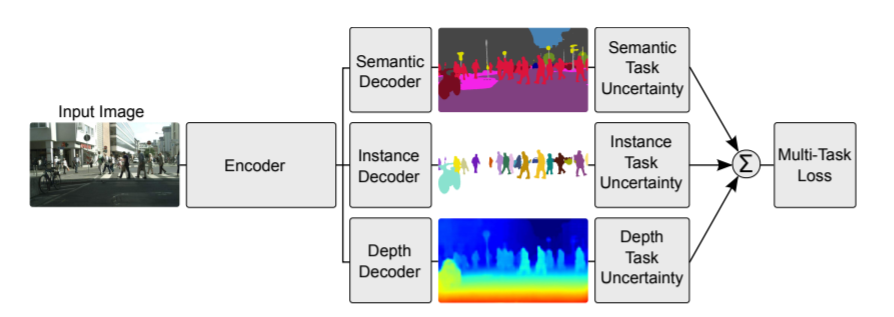
이번 글은 Multi-task learning과 Meta-learning 알고리즘 비교와 특징을 비교하여 설명한다. Multi-task learning은 처음 딥러닝을 공부할 때부터 많이 들어온 알고리즘이다. 알고리즘의 목적은 여러 task를 함께 풀어내어 좋은 성능을 내는 것이다. 여러 task를 함께 학습하여 general 한 feature를 뽑게 하여 학습에 도움을 주며 한 번에 여러 개를 풀 수 있으므로 efficient 한 장점이 있다. Meta-learning은 익숙하지 않은 경우가 많을 것 같다. 논문은 많이 나왔지만 실제 사용하여 문제를 푸는 경우는 거의 못봤기 때문인 것 같다. 알고리즘의 목적은 unseen task에 대해 few 개의 데이터를 주었을 때 그것을 빠르게 학습하도록 만드는 ..