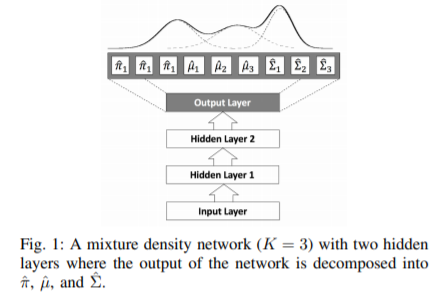
"Uncertainty-Aware Learning From Demonstration Using Mixture Density Networks with Sampling-Free Variance Modeling" - Sunjun Choi (2017) https://www.edwith.org/bayesiandeeplearning/joinLectures/14426 이번 논문은 Mixture Density Network 구조를 이용하여 Sampling을 하지 않고 Uncertainty를 알 수 있는 모델링 방법을 제시하였다. 2가지 Uncertainty에 대해 비슷한 의미를 가진 용어가 많이 사용되는데 여기서 정리하고 시작한다. (Uncertainty를 variance로 혼용해서도 사용한다.) Aleatoric U..