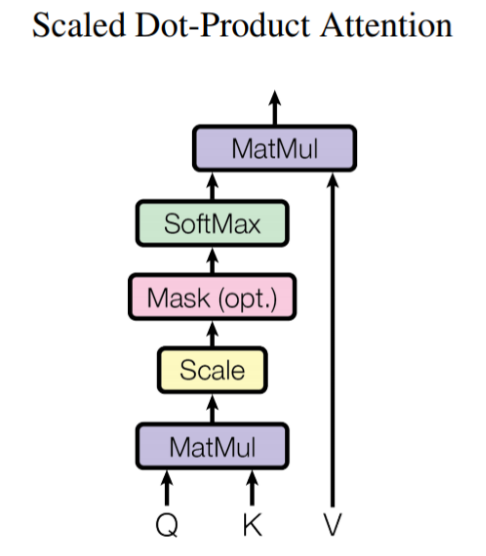
"A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction"(2017) - Yao Qin et al. https://dacon.io/competitions/official/235584/overview/ 이번 글에서는 Attention 기법을 Encoder와 Decoder에서 두 번 사용하는 Dual-Stage Attention 기반의 RNN을 이해하고 구현해 볼 것이다. 참고한 논문에서는 주가 데이터를 이용하여 모델을 사용하였지만 여기서는 Dacon에서 주관하는 온도 추정 경진대회의 데이터를 사용하였다. 데이터 설명 온도 추정에 사용되는 변수는 40가지이며 각각의 데이터는 다음과 같은 8개의 분류로 5개씩 존재한다. ..