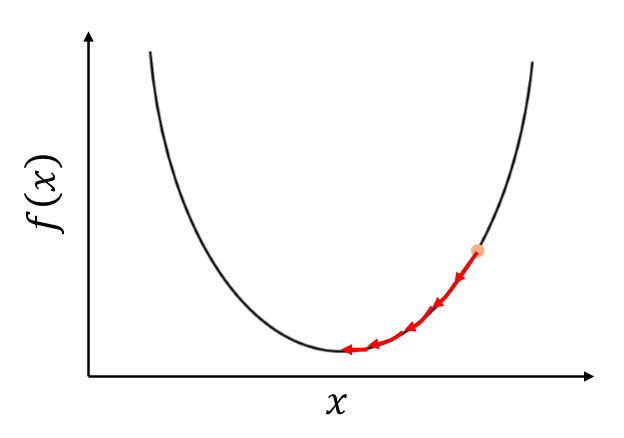
이번에는 경사하강법을 이용해 최적화를 할 때 Learning Rate(학습률)을 사용하는 이유를 알아 볼 것이다. 경사하강법은 이전 글에서 작성한 것처럼 Loss값을 줄이는 과정으로 파라미터를 업데이트하는 과정인데 이를 수식으로 작성하면 다음처럼 표현할 수 있다. $L(\theta+\Delta \theta) < L(\theta)$ 위의 조건의 만족되면 Loss가 계속 줄어가는 것이니 학습이 잘 되는 것이다. $L(\theta+\Delta \theta)$ 를 Taylor 정리를 사용하면 다음과 같이 나타낼 수 있다. $$L(\theta+\Delta \theta) = L(\theta) + \bigtriangledown L * \Delta \theta + \frac{1} {2}\bigtriangledown^{..