TD3 (Addressing function approximation error in actor-critic methods ([1]))
TD3라고 알려진 방법은 Double-Q learning에서 network를 2개 만들어 maximization bias를 피하는 방법을 쓰는 것이 이전 글에서 소개한 DDQN에서 target network를 학습 network에서 복사해서 사용하는 것보다 좋다고 주장한다. 하지만 기존처럼 Q-learning이 아닌 Actor-critic을 전제로 한다. 저자는 Actor-critic에는 overestimation bias와 가치함수 추정치의 분산 문제가 있어 학습을 불안정하게 만든다고 주장한다. 실제 실험 결과를 보면, DDPG 알고리즘도 overestimation bias 현상이 일어나고 있고 논문에서 제안한 CDQ 방법이 더 안정적 성능을 내는 것으로 보이며(Fig 1), DDQN 방법보다 Double Q-learning 방법이 overestimation bias 문제를 완화시켜 준다.

CDQ(Clipped Double Q-learning)은 기존 Double Q-learning 같이 Q-network를 따로 생성하여 2개 사용하는 방법이다(Actor-Critic에서는 정책도 따로 만드는게 맞지만 여기서는 효율을 위해 한 개만 생성한다). 기존과 다른 점은 target을 만들 때 2개 중 minimum 값을 사용한다는 점이다. 이를 통해 overestimation bias 문제를 완화시켜 준다.
$$ Target = r+\gamma min_{i=1,2} Q_{\theta_{i}} (s', \pi_{\phi}(s')) $$
한편 function approximation으로 인한 에러로 인해 분산이 커지는 문제도 있다. Target network가 제대로 추산되지 않을 경우가 문제인데, 이는 policy 업데이트 시 악영향을 끼친다. 따라서 가치함수 추산 오차를 줄이기 위해 가치함수를 정책보다 더 자주 업데이트 하는 방법을 제시한다. (2개 네트워크를 같이 업데이트하는 것은 당연히 어렵고 오차가 클 수밖에 없을 듯하다.)
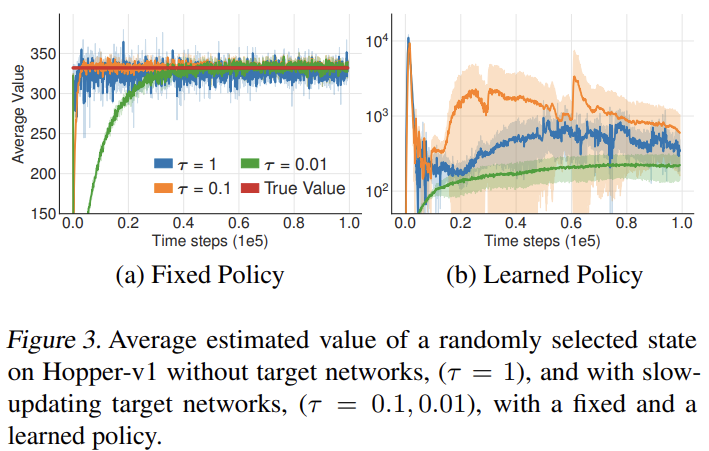
Fig 2는 정책을 고정했을 때와 학습했을 때 target network를 업데이트하는 정도에 따라 value 추정치의 분산을 확인한 것이다. 확실히 slow update 방법이 좋은 효과를 보인다. ( $ \theta \leftarrow \tau \theta + (1-\tau)\theta' $)
Determinisitc policy에서는 정책이 디렉-델타 함수와 같이 narrow 분포를 가질 수 있다. 이 또한 function approximation으로 인한 오류로 target variance가 증가하게 한다. 그래서 target policy smoothing regularization을 도입한다. 이는 동일한 state에서 유사한 정책의 경우 유사한 값을 가지게 하는 것으로 정책 분포가 좀 더 넓어지게 만들어주는 효과가 있다. 방법은 아래 수식과 같이 gaussian noise($\epsilon$)로 perturb를 주는 방법이다.
$$ Target = r + min_{i=1,2} \mathbb{E}_{\epsilon} [Q_{\theta'_{i}}(s', \pi_{\phi}(s') + \epsilon) ] $$
(실제 구현시에는 noise에 대해 기댓값 계산을 하진 않고 one-sample mc로 추정한다.)

알고리즘을 확인해보면, 위에서 설명한 방법들을 모두 쓰고 있는데 특히 policy gradient를 가끔 업데이트시키는 부분을 보면 target network도 soft update를 사용해서 같이 업데이트하는 것을 볼 수 있다. 여러모로 분산을 줄이고 최대한 안정적으로 훈련시키기 위해 여러 가지를 고려했음을 볼 수 있다.

Fig 4의 실험 결과를 보면 TD3가 average return이 높을 뿐 아니라 안정적으로 학습되는 모습을 볼 수 있다. RL은 학습 기반의 stochastic optimization 방법이라 어려워서 디테일한 방법 혹은 트릭이 중요하게 작용되는 것 같다.
Ref
[1] https://arxiv.org/abs/1802.09477
'머신러닝&딥러닝 > 강화학습' 카테고리의 다른 글
| PPO paper 리뷰 (1) | 2023.12.13 |
|---|---|
| DQN 부터 DDPG 까지 정리 (0) | 2023.12.02 |
| RL 기초 개념 정리 (0) | 2023.11.24 |
| 강화학습 기초 다지기 (2) - 강화학습 문제 풀이 기법 (DP, MC, TD) (0) | 2022.05.08 |
| 강화학습 기초 다지기 (1) - 마르코프 (0) | 2022.05.01 |