"Averaging Weights Leads to Wider Optima and Better Generalization" - Pavel Izmailov (2019)
이번 논문은 Stochastic Weigths Averaging(SWA) 방법을 제시한 논문이다. 여러 캐글 대회에서 이 방법을 사용하여 우승을 하는 경우를 봐서 논문을 리뷰하게 되었다.
Introduction
SWA는 기존의 SGD 보다 더 flatter 한 solution을 찾는 방법이라고 설명한다. 그래서 generalization에 강하여 test 셋에서 훨씬 좋은 성능을 보인다. 방법 또한 간단하여 기존과 계산량 차이가 거의 없어 효과적이라 할 수 있다. SWA는 SGD를 이용하여 optimization을 진행할 때 일정 주기마다 weight를 average하여 $w_{swa}$를 update 시키는 방법이다.(SnapShot Ensembles 방법 이다.) 논문에서 SWA는 optimization과 regularization과 관련있다고 한다. 여러 주기마다 weight를 update 시키는 것은 local solutions를 ensemble 하는 것과 같다고 이해할 수 있다. 따라서 어느 한쪽에 쏠리는 것을 막아 regularize를 수행하며 general 한 solution을 찾게 된다. loss surface에서 대략적인 sampling을 하여 가중치를 업데이트 한다는 개념이 베이지안적 접근이라는 생각을 했다. 마지막 Discussion에도 이에 대한 내용이 나와 있다. Cyclical learning rate을 사용하면 SWA가 neural network weights에 대한 high posterior density를 탐험하는 것을 가능하게 한다. 이는 MCMC 방법과 유사하다.
Algorithm
SWA를 수식으로 나타내면 아래 그림과 같다.

개념만큼이나 수식 또한 간단하다. SGD가 각 step마다 weight를 업데이트 시키는데 일정 주기마다 $w_{swa}$를 average값을 내어 업데이트시킨다는 것이 끝이다.
Experimental result
1) 논문에서 Learning rate를 중요하게 다루고 있는데 SWA를 사용할 때는 Constant 한 값과 Cyclical 한 값을 추천한다. 아래는 두 learning rate를 사용했을 때의 결과를 나타낸 그래프이다.

왼쪽 두개는 Cyclical learning rate schedules을 사용한 것이고 오른쪽은 Constant learning rate schedules을 사용한 것이다. 우선 Cyclical learning rate schedules는 individual한 성능이 Constant learning rate 보다 일반적으로 더 정확하다. 하지만 Constant learning rate은 상대적으로 항상 큰 step으로 업데이트가 되어 Cyclical learning rate 보다 더 효과적인 탐험을 가능하게 한다는 장점이 있다. 따라서 어떤 task를 해결하냐에 따라 둘 다 사용하여 더 나은 것을 선택하는 것이 좋을 것이다.
2) 이어서 Preactivation ResNet-164로 CIFAR-100를 학습할 때, 여러 Learning rate scheduels로 실험을 했다. 결과는 아래와 같다.
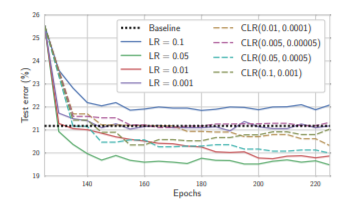
가장 좋은 LR은 0.05였다. 일반적으로 0.05는 learning rate 치고 큰 편에 속하는데 이렇게 큰 learning rate을 사용하면 많은 탐색이 가능하며 SWA를 빠르게 수렴하도록 하는 좋은 결과를 낸다고 한다. 하지만 논문에서는 어떤 문제를 푸느냐에 따라 다르다고 하였으니 각 문제마다 hyperparmeter 탐색을 잘해야 할 것이다.
fixed learning rate으로 SWA를 사용한 실험에서 처음부터 SWA를 사용하여 학습을 시킨 모델보다 처음에는 그냥 SGD를 사용하고 중간부터 SWA를 사용한 모델이 16%정도 더 정확한 모델이 나왔다고 한다. 이렇게 중간부터 SWA를 사용하면 더 빠르고 안정적이게 수렴한다고 한다.
3) 기존의 알고리즘들과 SWA를 ImageNet이나 CIFAR-10, CIFAR-100에 적용하여 성능을 비교하였는데 기존 SGD보다 항상 좋은 성능을 냈다.
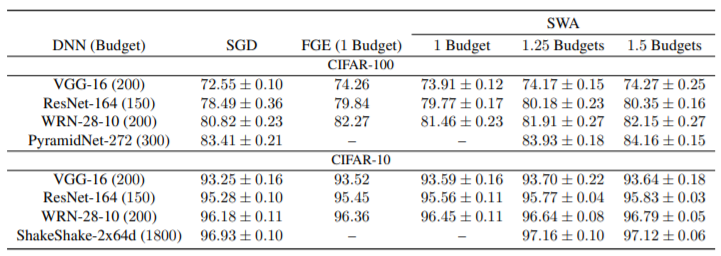
논문에서 Fast Geometric Ensembling(FGE)라는 알고리즘을 자주 언급하며 비교한다. 직접 읽어보진 않았지만 FGE는 weight space에서 가까운 포인트들을 생성하며 거기서 여러 Prediction을 내어 Ensembling 하는 알고리즘을 사용한다고 한다. 이에 따라 FGE는 계산량이 SWA보다 많을 수밖에 없다. 하지만 성능을 비교해봤을 때는 거의 비슷하며 CIFAR-10에서는 더 나은 결과를 내기도 하였다. 논문에서는 수식을 사용하여 prediction을 ensemble 하는 것과 weight를 ensemble 하는 것은 second order만큼의 작은 차이가 난다는 것도 증명하였다.
개인 실험
개인적으로 SWA를 사용해보고자 Pretrain 된 RESNET-50 모델을 CIFAR-10에 적용하여 성능을 비교하는 실험을 해보았다. 논문에서는 SGD만 사용하였지만 자주 사용하는 Adam도 성능이 잘 나오는지 궁금하여 같이 진행해 보았다. learning rate은 0.05를 사용하였다. train set은 5만 장, test set은 1만 장을 사용하였다. 총 5 epoch만 진행하였으며 $w_{swa}$는 10 step마다 업데이트하도록 하였다. tensorflow 2.3 version을 사용하였다. training에 대한 결과 그래프는 아래와 같다.

test set에 대한 결과는 adam:0.21, swa_adam:0.26, sgd:0.53, swa_sgd:0.56 이었다. 여러 번 실행을 하였을 때 SGD의 경우 swa가 더 잘 나오는 결과를 얻었다. 하지만 Adam은 training마다 결과가 잘 나올 때도 있고 그렇지 않을 때도 있었다. learning rate을 너무 크게 설정해서 그럴 수도 있다.
혹시 개인적으로 돌리고 싶은 분들이 있다면 깃헙에 올려놨으니 colab을 사용하여 코드를 실행시키시면 됩니다.