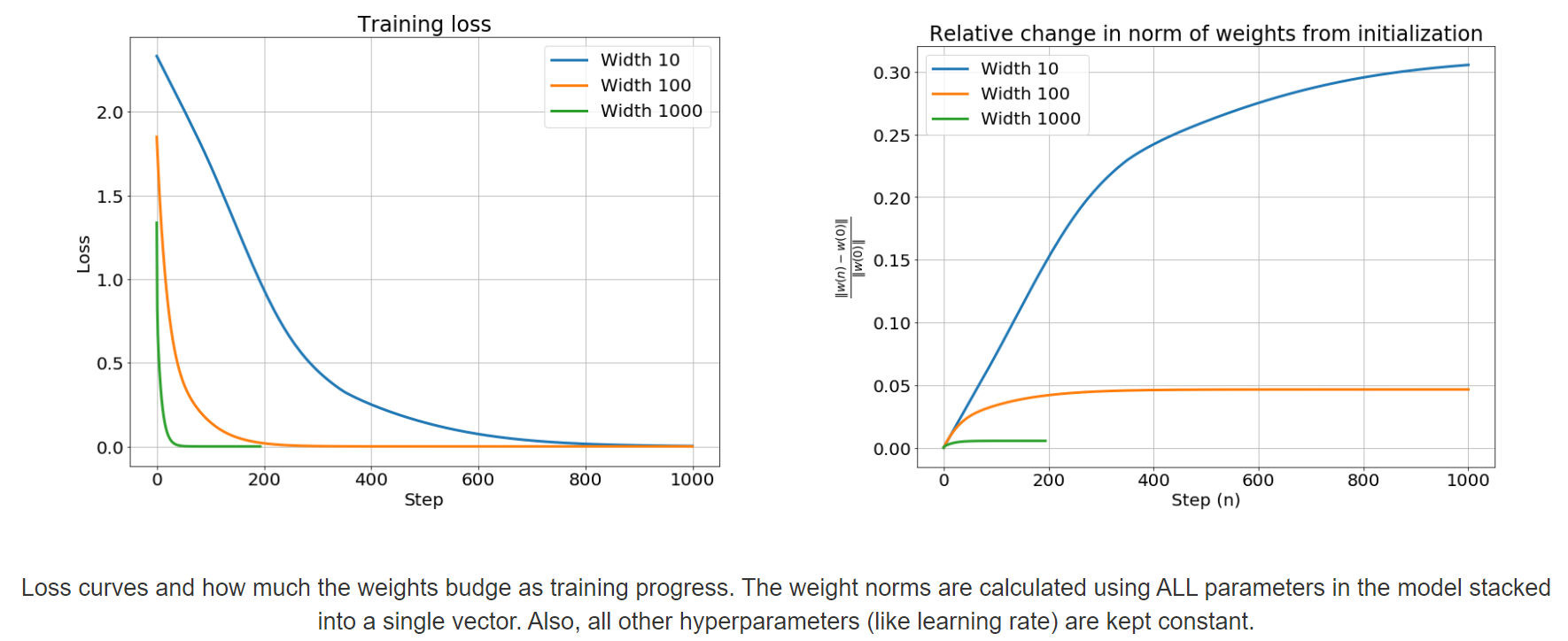
이번에 리뷰할 Neural Tangent Kernel (NTK) 논문은 NIPS 2018에 실린 논문으로 많은 인용수를 자랑하는 파급력 높은 논문입니다. 하지만 논문을 이해하려면 수학적 배경지식이 많이 필요해서 읽기가 어렵습니다. 다행히 설명을 잘해놓은 외국 블로그([2])가 있어 많은 참고를 하였습니다. 이 논문은 2 hidden layer와 infinite nodes의 neural network는 linear model로 근사하여 생각할 수 있고, 그 덕분에 문제를 convex 하게 만들어 해가 반드시 존재한다는 것을 보여줍니다. 어떻게 linear model로 근사하여 생각할 수 있다는 것인지 차근차근 알아보겠습니다. Taylor Expansion Taylor expansion은 매우 작은 영역에서..