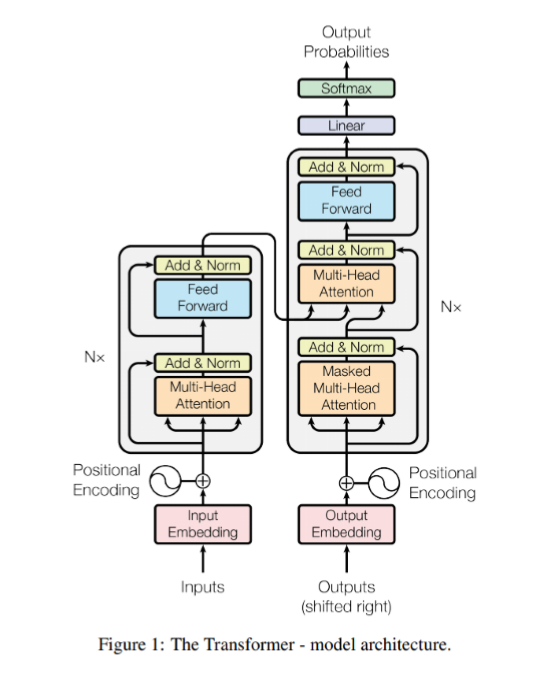
Transformer는 기존의 모델들과 달리 CNN의 Convolution이나 RNN의 Cell들을 이용하지 않아 낯설게 느껴져서 다시 한번 모델의 총과정을 리뷰한다. Transformer의 Input data로 Embedding 된 벡터를 넣어주는데 이때 들어가는 벡터에 Positional Encoding 방법으로 벡터의 순서를 표시해준다. 다음으로 Multi-Head Attention에서 self-attention을 수행해주고 단어 간의 관련도를 계산해준다(query, key, value가 모두 같은 sequence가 된다). 이 과정이 Transformer의 성능을 끌어올리는 핵심이다. Attention의 내적연산으로 같은 문장 내 단어끼리의 의미적, 문법적 관계를 포착해내는 중요한 과정이다. Mu..